
 LinkBack URL
LinkBack URL About LinkBacks
About LinkBacks






 Citar
CitarNo tengo palabras Tassadar. Impresionante.
Mi más sincera enhorabuena por este articulazo (y por muchos otros con los que nos deleitas).
He aprendido cosas nuevas gracias a él, aunque creo que lo deberé leer de nuevo para sacarle más jugo.")



Regístrate para eliminar esta publicidad
A veces nos encontramos comentarios del tipo "en estos nuevos procesadores se ha aumentado el pipeline". Esta afirmación es imposible de descifrar o saber si es beneficioso o perjudicial si no sabemos lo que es.
Pues bien, en una primera aproximación al concepto vamos a explicarlo de la manera más simple posible, sin entrar en muchos detalles, para al menos poder entender como afecta:
1.-Aproximación a lo que es el pipeline
En un procesador las instrucciones se ejecutan o procesan en ciertos pasos (como las fases de una cadena de montaje). Las etapas del pipeline (su longitud) son esas etapas o pasos por las que pasa una instrucción para ser procesada.
El dividir en más pasos la tarea de procesar una instrucción hace que el procesador pierda IPC, o sea, que ejecute menos instrucciones en cada ciclo de reloj, pero tiene el efecto positivo de que el procesador puede ir a más frecuencia, o sea, ir a más mhz.
En un símil con los motores:
Supongamos que tenemos un motor de un coche de 2000 centímetros cúbicos que es capaz de funcionar a 4000 rpm. Este motor a 4000 rpm nos da 100 caballos de potencia. El motor tiene un pipeline de 12 etapas, o sea, la gasolina pasa por 12 pasos desde que entra en el motor hasta que se quema y sale por el tubo de escape (obviamente esto de los 12 pasos de la gasolina es totalmente falso, lo usamos solo como ejemplo para entender de lo que hablamos acerca del pipeline).
Aumentar el pipeline del motor de 12 a 20 etapas haría que la gasolina pasase por 20 pasos en lugar de 12. Esto haría que el motor, funcionando a esas 4000 rpm nos de solo 80 caballos de potencia.
Puede parecer entonces que no tiene sentido aumentar el pipeline, ¿verdad?. Pues bien, la cuestión es que aumentar el pipeline hace que el motor pueda funciona a más rpm (más mhz o ghz en el caso de los procesadores), con lo cual ahora el motor de 2000 centímetros cúbicos puede funcionar a 5500 rpm, y resulta que a 5500 rpm nos da 110 caballos.
Resultado: ha merecido la pena aumentar el pipeline porque el resultado es que el mismo motor de 2 litros (2000 centímetros cúbicos) ahora nos da más potencia (10 caballos más).
Podríamos pensar que la solución entonces es aumentar el pipeline hasta el infinito y con eso tendremos mucho más rendimiento, pero no es así, porque para que esto ocurra el aumentar el pipeline debe traer como consecuencia que la frecuencia aumente lo suficiente como para no solo contrarrestar la pérdida de rendimiento, sino que además la supere.
En el ejemplo del motor del coche, si al aumentar el pipeline nos hubiera dejado subir solamente hasta 4500rpm desde las 4000 originales, no habría sido "un buen negocio" porque entonces nos habríamos quedado en 90 caballos, 10 menos que con el motor original que funcionaba a 4000rpm.
Como ejemplo de esto que comento que no siempre merece la pena, el Pentium 4 tiene el gran honor de ser muestra fehaciente para ilustrarlo.
Bueno, hasta aquí una explicación sin entrar en detalles del tema, para que podamos saber a qué se refiere esto del pipeline y cómo influye. Ya podéis dejar de leer
2.- Análisis a fondo y explicación del concepto
Para los que queráis llegar al "meollo de la cuestión" y saber el porqué real del tema, abrocháos los cinturones que el camino es movidito...
¿Como funciona un procesador o CPU?
Los programas informáticos se componen de muchas instrucciones, y el procesador ha de ir procesando esas instrucciones para que el programa vaya funcionando. Entendamos un procesador como una fábrica donde se produce la manufactura de un bien, en este caso en bien que manufacturamos no son ni coches ni plasmas VT70 o HTPCs, ni nada "físico y tangible"; en el procesador lo que fabricamos son esas "instrucciones".
El procesamiento de una instrucción ha de pasar por un mínimo de 4 fases:
1.-Lectura: Busca la instrucción que toca ejecutar ahora.
2.-Decodificación: Decodificar la instrucción que se ha leído.
3.-Ejecución: Hallar el resultado de la instrucción
4.-Escritura: Escribir el resultado en el registro correspondiente.
Cada una de estas etapas se denomina "etapa del pipeline" y la profundidad de éste es el número de etapas que tiene. Estas cuatro son el número mínimo de fases que puede existir en un pipeline, con lo cual es la mínima profundidad posible (sería un pipeline de 4 etapas).
2.1.-Artículo similar en Ars Technica
Se suele usar el símil de la fabricación de automóviles para explicar el pipeline, así que yo no voy a ser quién ponga otro ejemplo mejor.
De hecho, en ArsTechnica publicaron hace años un artículo tratando el tema:
Pipeline explicado en Ars Technica (en inglés), -parte 1-
Pipeline explicado en Ars Technica (en inglés), -parte 2-
Dado que en nuestra opinión es posiblemente el artículo de internet que mejor trata el tema, vamos a usar los gráficos de ese artículo e irremediablemente parte de su estructura, porque para nosotros es la mejor para explicar el concepto.
Eso sí, aclarar que este artículo no es una traducción de ese. Aunque el símil en ambos casos es con los coches y hemos aprovechado sus gráficos, y la estructura del artículo es, casi irremediablemente, similar en muchos puntos; los ejemplos y forma de explicarlo varían y son propias, y hay cosas que explicamos en este artículo y no se explican en el de Ars Technica, y viceversa.
2.2.-El símil de la construcción de coches
Imaginemos que montamos una fábrica de coches. Lo primero que necesitaremos es estudiar cómo se construye un coche y las fases de contrucción que tendrá. Necesitaremos unas instalaciones con el equipamiento necesario (tanto humano como herramientas y medios técnicos) para poder realizar esta tarea (no podemos hacerlo en el salón de nuestra casa).
Tras hacer un análisis vemos que hay 4 fases que necesitan personal cualificado específico para esta terea y una parte de la fábrica destinada a tal fin. Necesitaremos:
1.-Chasis del coche: Esta tarea implica contruir todos los elementos del chasis y su integración.
2.- Pintar el Chasis: Poco que explicar...
3.-Motor: Esta tarea implica contruir el motor y ponerlo en el chasis.
4.-Interiores: Colocar puertas, interior, ruedas y el resto de elementos del coche.
Son cuatro fases independientes; para cada una contaremos con trabajadores que saben hacer esta tarea y máquinas que sirve para llevarla a cabo. Las personas que saben como hacer el chasis no saben pintar, ni saben de motores, ni tampoco de ruedas o interiores y lo mismo pasa con la maquinaria. Por lo tanto, los recursos que usamos para cada una de las 4 tareas no nos valen para las otras tres tareas.
"Curiosamente" nos han salido 4 fases en la construcción del coche, las mismas que en el procesamiento de una instrucción en el procesador. Ya tenemos claro que en el procesador habrá partes que hagan una tarea y partes que hagan otra, al igual que en nuestra fábrica de coches.
Nuestra fábrica tiene un "pipeline de 4 etapas".
2.3.-¡Comienza la producción!
Ya tenemos nuestra fábrica montada, comenzamos a construir coches.... el proceso es:
Ahora el equipo 1 recibe material para el segundo coche, y se ponen manos a la obra, repitiéndose el proceso....1.- Primera hora
*Entra material en la fábrica y el equipo 1 empieza a construir el chasis, mientras tanto, los otros 3 equipos están de brazos cruzados. Pasada una hora el chasis está construido.
2.- Segunda hora
*El equipo 1 pasa al equipo dos el chasis, y éste lo pinta, tardando una hora. Cuando han pasado dos horas desde que comenzó el proceso el equipo dos pasa el chasis recién pintado al equipo 3.
3.- Tercera hora
*El equipo 3 construye el motor y lo integra en el chasis. También tardan una hora, y cuando acaban le pasan el coche al equipo 4.
4.- Cuarta hora
*El equipo 4 hace su trabajo y cuando acaba (tardan también una hora), tenemos el coche listo.
Con esta forma de trabajar tardamos 4 horas en fabricar un coche, y hemos tenido cuatro equipos de profesionales implicados esas cuatro horas.
Cada equipo está cualificado para hacer su trabajo, no el de los demás, por lo que realmente cada uno ha pasado tres de las cuatro horas esperando a que los otros equipos hiciesen sus tareas.
Consecuencia: En fabricar un coche hemos tardado 4 horas, en fabricar 2 tardaríamos 8, en fabricar 3 tardaríamos 12.... y así sucesivamente.
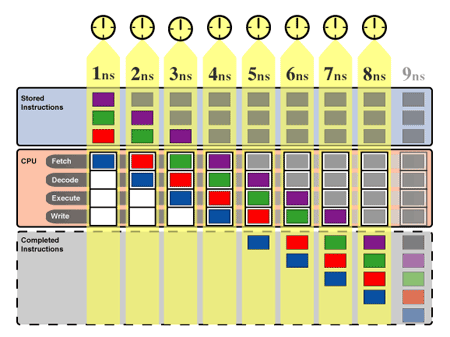
En este gráfico vemos el diagrama de tiempo y de procesamiento de las instrucciones (o fabricación de coches) de ocho horas:
Arriba vemos 1ns, 2ns, 3ns... esto son los nanosegundos de tiempo, en la fabricación de coches serían horas.
Si por ejemplo vamos a construir 4 coches, uno azul, otro rojo, otro verde y el último morado, vemos que en la primera hora el equipo 1 (Chasis para los coches, Lectura para las instrucciones, en el gráfico "Fetch" porque está en inglés), trabaja en el coche azul, a la siguiente hora trabaja el equipo de pintura (decode -decodificación-), tercera hora.... (tal como hemos explicado antes).
Al acabar la hora 4 el primer coche está acabado y entra en la fabrica el coche rojo... resultado, se tarda 4 horas en cada coche.
¿No os parece un desperdicio de recursos? ¿No habriá alguna manera de hacer que los equipos pasasen más tiempo trabajando y menos esperando?
2.4.-Introduciendo el montaje en cadena
La fábrica funciona, pero tardar 4 horas en fabricar un coche es demasiado, así que vamos a aprovechar mejor nuestros recursos, haciendo que mientras un equipo está trabajando en un coche, los demás equipos también estén trabajando con otros coches.
Introduciendo el montaje en cadena en nuestra fábrica el proceso para los cuatro coches sería así:
Conclusión: No podemos negar que el aumento de producción ha sido muy importante. Con el procedimiento anterior habríamos tardado 4 horas en cada coche, haciendo un total de 4*4= 16 horas en fabricar los 4, ahora hemos tardado solo 7 horas.1.- En la primera hora:
*El primer equipo hace el chasis del primer coche, el azul. En este tiempo, los otros tres equipos están sin hacer nada.
2.- Segunda hora:
*Al igual que en nuestra forma de funcionar anterior, el segundo equipo toma el coche azul que le pasa el primer equipo y lo pinta (esto era así antes también).
La diferencia es que ahora el primer equipo, en lugar de esperar que los otros tres acaben el primer coche, se ponen con el segundo coche, el rojo.
Eso sí, los equipos tres y cuatro aún no pueden hacer nada.
3.- Tercera hora:
*El primer equipo ha acabado el segundo coche (rojo), y se lo pasa al equipo dos para que lo pinte. Ahora el equipo uno empieza con el coche verde.
*El segundo equipo que ya ha pintado el azul, se lo pasa al tercer equipo (que no había podido hacer nada en las dos primeras horas) y se pone a pintar el rojo que le pasa el equipo 1.
*El equipo tres como ya hemos dicho se pone con el coche azul que le pasa el equipo dos.
*El equipo azul aún no está haciendo nada en esta tercera hora.
4.- Cuarta hora
*Cada equipo (1, 2 y 3) ha completado su tarea con otro coche, y se lo pasa al siguiente equipo. Tras tres horas sin hacer nada el equipo 4 se pone con el coche azul (el primero), que ya ha pasado por los otros tres equipos.
*En esta cuarta hora todos los equipos están trabajando.
5.- Quinta hora.
*En esta quinta hora. tras pasar cada equipo su coche al siguiente equipo, el cuarto equipo da salida al primer coche (el azul).
*El equipo dos está con el coche morado, el tres con el verde y el cuarto con el rojo, pero el primer equipo ya se ha quedado sin nada que hacer, y tras haber montado el chasis de los cuatro coches en las cuatro primeras horas, no tiene más chasis que montar.
6.- Sexta hora
Ahora son dos equipos los que han acabado los 4 coches (equipo uno y dos), mientras, los equipos 3 y cuatro siguen trabajando en los coches morado y verde respectivametne.
7.- Séptima hora
Los tres primeros equipos ya han acabado con los 4 coches, solo queda trabajando el equipo cuatro con el último coche.
8.- Octava hora.
Ningún equipo tiene ya trabajo que hacer, hemos tardado 7 horas en fabricar 4 coches.
Pero esto sigue estando muy lejos de las dos horas que podríamos haber tardado si todos los equipos hubieran estado trabajando las cuatro horas.
Es importante ver que respecto a la forma que lo hacíamos antes hemos tardado 7 horas en lugar de 16 en fabricar los 4 coches, pero cada coche sigue estando 4 horas en fase de montaje, al igual que antes.
Producción máxima con este método
Resulta obvio que si en lugar de haber tenido que satisfacer un pedido de 4 coches hubiésemos tenido un pedido de.... digamos 8 coches.... habríamos sido mucho más eficientes, de hecho con éste metodo 8 coches los habríamos tenido en solo 11 horas (que sigue lejos del ideal de 8 horas que habríamos tardado en hacer 8 coches con todos los equipos trabajando todo el tiempo).
Cuanto mayor sea el pedido, más eficientes seremos, porque más tiempo estarán simultáneamente todos los equipos. En el ejemplo de los cuatro coches solo hemos tenido esta situación ideal (los 4 equipos trabajando) durante una hora, con un pedido de ocho coches los cuatro equipos habrían estado trabajando al mismo tiempo durante 5 horas.
De todas formas, es una realidad que la producción máxima con esta forma de trabajar es de un coche a la hora, y esto en una situación ideal de que los 4 equipos estén trabajando.
En el procesador, esto significa que el máximo rendimiento será de una instrucción procesada cada milisegundo, contando que las 4 etapas del pipeline estén llenas.
2.5.-¿Como aumentar la productivividad?
Ya tenemos claro que el fabricar en cadena nos hace aumentar drásticamente la producción, pero también sabemos que inevitablemente habrá momentos donde no todos nuestros equipos de trabajo estén trabajando, y que lo ideal será cuando todos estén con un coche entre manos.
¿Y si los turnos de trabajo que tenemos en lugar de ser de una hora fueran de menos tiempo?... no se... digamos que los turnos son de media hora en lguar de una, ¿podríamos hacer esto?. En un procesador esto supondría aumentar la frecuencia, pasar por ejemplo de 1 ghz a 2 ghz.
Hacer esto supondría que los trabajadores y la maquinaria tienen que trabajar el doble de rápido, lo cual hará que estén estresados, sometidos a mucha presión y posiblemente comentan muchos errores, bloqueando totalmente el funcionamiento de la fabrica y produciendo coches defectuosos (de hecho esto es justo lo que pasa cuando hacemos demasiado overclock a un procesador, que no es "estable", que da errores, se bloquea el ordenador, etc).
Esto es simple y llamamente porque cada uno de los cuatro equipos tiene asignada una tarea que para completarse requiere una hora, no se puede hacer en menos tiempo.
¿Y si pudiésemos simplificar las tareas para que se tardase menos?. Por ejemplo, la primera tarea, la de montar el chasis del coche la vamos a dividir en dos sub-tareas, o directamente en dos tareas independientes:
1-1.- Construir bastidor del coche (la parte de abajo, la base)
1-2.- Construir puertas, capó y techo.
Haciendo esto aumentaríamos la cadena de montaje de cuatro a cinco equipos, y así para estas nuevas dos tareas podríamos fijar turnos de media hora porque son tareas mas simples y se tarda menos.
Pero.... claro, ¡no hemos resuelto nada!, porque aunque es cierto que para las dos tareas que salen de descomponer la tarea uno podemos fijar turnos de media hora, las otras tres tareas siguen teniendo una complejidad tal que se tarda una hora.
Dado que es montaje en cadena de nada nos sirve tener equipos que sean capaces de hacer su trabajo en media hora si hay otros que tardan una hora, porque entonces los que tardan una hora estarán limitando la productividad de los que tardan menos.
Precisamente esta es una de las mayores dificultades a la hora de diseñar procesadores, todas las tareas del pipeline deben poderse realizar en el mismo tiempo, ya que si unas tareas son más complicadas que otras, estos equipos que tardan más serán el "cuello de botella" de la producción.
De nada serviría que casi todas las tareas se puedan hacer en media hora si existe alguna que requiere una hora, pues los turnos de trabajo, tendrían que ser de una hora para que ese equipo que tarda una hora pueda hacer su tarea.
Vamos entones a crear tareas que se puedan hacer en media hora, para esto dividiremos las 4 tareas actuales en las que se tarda una hora:
1.-Chasis del coche: Esta tarea implica contruir todos los elementos del chasis y su integración.
1-1.- Construir bastidor del coche (la parte de abajo, la base)
1-2.- Construir puertas, capó y techo.
2.- Pintar el Chasis: Poco que explicar...
2.1.- Pintar puertas y capó
2.2.- Pintar resto del coche (techo, etc)
3.-Motor: Esta tarea implica contruir el motor y ponerlo en el motor.
3.1.- Contruir bloque de motor
3.2.- Construir radiador, batería, circuito de refrigeración, etc.
4.-Interiores: Colocar puertas, interior, ruedas y el resto de elementos del coche.
4.1.- Colocar puertas e interior
4.2.- Colocar ruedas y resto de elementos del coche.
Ahora sí, hemos pasado de cuatro equipos complejos de trabajo a ocho equipos más simples, y cada tarea en lugar de necesitar una hora de trabajo necesita solamente media.
Hemos aumentado el pipeline, esto se hace para poder aumentar la frecuencia de funcionamiento, en este caso el aumento es enorme pues hemos duplicado la frecuencia (es como si nuestra fábrica hubiese pasado de funcionar a 1Ghz a funcionar a 2Ghz
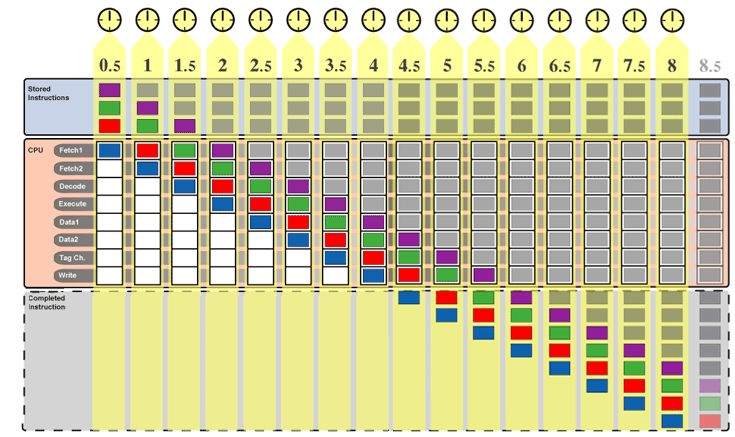
El esquema de funcionamiento ahora para fabricar un pedido de 4 coches sería este:
Es muy importante notar que el primer coche (el azul) está listo justo después de 4 horas, y esto ocurre siempre así, ocurría al principio cuando los equipos trabajaban uno a uno, ocurria después cuando introdujimos la fabricación en cadena y sigue ocurriendo ahora que hemos pasado de cuatro a ocho equipos de trabajo (pipeline de 4 a 8 etapas).
¿Que diferencias observamos ahora con los 8 equipos?
A partir de que sale el primer coche fabricado, con el primer modelo de fábrica tardábamos cuatro horas en tener cada coche listo.
Después al hacer que los equipos se fuesen pasando el trabajo de unos a otros, con cuatro equipos, después del primer coche teníamos listo un coche cada hora.
Ahora, con los 8 equipos, tras ese primer coche, tenemos un coche más cada media hora, o sea, ¡hemos duplicado la tasa máxima de producción!.
Eso sí, los cuatro coches los tenemos ahora listos tras 5,5 horas, mientras antes con 4 equipos estaban tras 7 horas, con lo que la diferencia no es demasiado impresionante. Claro está, la mejora será más notable cuantos más coches produzcamos, los 8 coches antes (con 4 equipos) los teníamos tras 11 horas y ahora tras 7,5 horas, lo cual sí que es una mejora mucho más considerable.
Conclusión: Aparentemente el aumentar la profundidad del pipeline supone una clara mejora en el rendimiento, siempre y cuando tengamos un mínimo de instrucciones que procesar (o coches que fabricar).
Pero no nos dejemos llevar por una conclusión precipitada, porque por lo pronto, el ejemplo que hemos puesto es tan idealista que es falso:
-Como ya hemos comentado, lo más complicado al crear un pipeline más largo es hacer que cada etapa lleve a cabo su tarea en el mismo tiempo que las demás.
-Simplemente por hacer un pipeline del doble de etapas es prácticamente imposible que podamos aumentar la frecuencia al doble, en nuestro ejemplo, el hacer turnos de media hora es como poco, "excesivamente optimista", lo más probable es que los turnos con los ocho equipos hubiesen pasado a ser de 40 o 45 minutos, pero media hora....
En consecuencia, seguiríamos teniendo un mejor rendimiento si fabricamos muchos coches, pero ya no sería tan clara la ventaja, y además, con cantidades bajas de producción habríamos perdido rendimiento. Por ejemplo con turnos de 40 minutos ya el primer coche no estaría listo tras 4 horas, sino tras 5 horas y 20 minutos.
2.6.-De la teoría a la práctica... no todo es color de rosa
Hasta ahora nos hemos centrado en crear unos equipos de trabajo, establecer unas tareas en las que se tardase una hora, introducir el montaje en cadena haciendo que cada equipo pueda estar trabajando en un coche diferente, y posteriormente hemos segmentado el trabajo, haciendo que la fábrica sea más completa, teniendo ocho tareas en lugar de cuatro, pero siendo tareas más simples que se pueden hacer en media hora en lugar de en una.
Volvamos ahora al montaje en cadena con 4 equipos y 4 fases (así simplificamos un poco).
Hemos asumido que cada tarea se hace en una hora, pero en la vida real existen imprevistos y/o situaciones problemáticas que al fin y al cabo pueden darse, y puede ser que lo que normalmente es una hora se alargue hasta... 3 horas por ejemplo.
¿Que queremos decir con esto? Pues que puede ser que en un determinado momento, el equipo primero (por ejemplo) tenga problemas montando un chasis de uno de los coches (vete tú a saber, los componentes venían en mal estado, hay que hacer un ajuste, o simplemente falta una pieza que es vital y tienen que esperar a que se la traigan....).
La situación sería esta:
En la quinta hora de trabajo (nanosegundo 5 en la imagen - 5ns) el equipo uno toma el coche naranja para montar su chasis, pero por alguna razón tiene problemas y no puede terminarlo en este turno.
Es por esto que en la sexta hora (nanosegundo 6 en la imagen - 6ns) el equipo 1 en lugar de pasar el coche naranja al equipo 2 y comenzar el montaje del coche rojo, sigue con el naranja.
Por su parte, el equipo 2 había acabado su labor con el coche morado, y lo pasa al equipo 3; y el equipo 3 que habia acabado su labor con el coche verde lo pasa al equipo 4; sin embargo, como el equipo 1 no pasa al equipo 2 el naranja, en esta hora el equipo 2 no tiene nada que hacer (vemos en el gráfico una burbuja).
Pasamos a mirar la hora 7 (nanosegundo 7 en la imagen - 7ns). El equipo uno sigue sin terminar con el coche naranja, con lo que el equipo 2 de nuevo no tiene nada que hacer, pero es que además, como el equipo 2 no le ha pasado ningún coche al equipo 3, ahora tanto equipo 2 como 3 están cruzados de brazos (o leyendo foroDVD con el móvil porque están mirando para comprar una tele, unos altavoces o un HTPC, pero esto a nosotros, como dueños de la empresa no nos produce nada).
En la hora 8 por fin el equipo ya ha terminado el coche naranja y se lo pasa al equipo 2, pero a causa del retraso, la "burbuja" de dos horas ahora la sufren los equipos 3 y 4 que están consultando ForoDVD en el móvil porque quieren comprar unos altavoces en lugar de trabajar.
En la hora 9, como consecuencia del imprevisto que ha afectado a todos los equipos de trabajo ningún coche nuevo sale de la cadena de montaje, pues el equipo 4 no ha tenido faena en la hora 8. Además, vemos en el gráfico que la "burbuja" aún la sufre el equipo 4, que sigue sin trabajar (los otros tres equipos si están ya trabajando con normalidad).
En la hora 10 la fabrica ha retomado el trabajo normal, con los cuatro equipos trabajando, pero como en la hora anterior (la 9) el equipo 4 no ha tenido faena, ahora tampoco sale ningún coche de la cadena de montaje.
En la hora 11 por fin sale un nuevo coche de la cadena de montaje y se ha recuperado la producción.
2.7.-Implicaciones de estos "imprevistos"
Estos imprevistos en el funcionamiento del procesador son lo que se conocen como "burbujas" o "atasques en el pipeline" ("bubbles", "pipeline stall" en inglés) y no son algo que pase muy de vez en cuando, sino que es algo que puede pasar y de hecho pasa por diferentes razones, siendo algo habitual.
Sin ahondar mucho, las razones por las que el pipeline puede atascarse, estas son:
2.7.1-Riesgos de Control
Ocurre cuando el procesador no "tiene la información necesaria", pues en el programa se producen saltos, ni mucho menos es siempre linear (existen saltos condicionales, bucles, saltos de programa...)
En los coches la fabricación de uno no depende de la fabricación de los demás, pero cuando de instrucciones se trata, esto ocurre muy a menudo.
Imaginemos que una instrucción es algo como:
Si los ingresos son mayores que los gastos entonces procesa "ganancias", si no, procesa "pérdidas"
Que "traducido" a los coches sería como algo como:
Dependiendo de como salga este coche de la fábrica, el siguiente coche es un monovolumen o un deportivo
El problema es que como tenemos una producción en cadena, el equipo uno pasa al equipo dos esta instruccion/coche tras montar el chasis, pero como el coche aun no está montado entero, no sabemos el resultado, entonces.... que hace el equipo uno, ¿se pone a montar un monovolumen o un deportivo?.
Lo normal sería que el equipo 1 ahora estuviera cruzado de brazos hasta que ese coche saliese de la fábrica, y dependiendo de como salga, se pondría a montar un deportivo o un monovolumen, pero claro, habríamos creado un atasco de 3 horas, 3 burbujas (el ejemplo que vimos anteriormente era de dos).
Y ahora pensemos... esto es con un pipeline de 4 etapas, con el pipeline de 8 etapas sería mucho peor, pues habríamos creado un atasco de 7 etapas, porque el coche del que depende qué construimos después tardaría 7 turnos en pasar por la cadena de montaje (y mientras, como no sabemos si contruir monovolumen o deportivo, no podemos hacer nada)
Es por esto que las penalizaciones en rendimiento son peores cuanto más largo es el pipeline. Es más complicado mantener todos los equipos de trabajo trabajando al mismo tiempo a medida que tenemos más equipos de trabajo.
Para esto hay cosas como la predicción de saltos. ¿Que es esto? Pues bueno... en lugar de tener la fábrica medio parada hasta que este coche salga de la fábrica y sepamos si lo siguiente a fabricar es un monovolumen o un deportivo, decimos "Yo creo que el coche va a salir de tal manera, así que lo siguiente va a ser un deportivo", y no paramos la fábrica, sino que el equipo uno se pone a construir un deportivo.
Si cuando el coche del cual depende que fabriquemos deportivos o monovolúmenes sale de la fábrica vemos que teníamos que haber fabricado deportivos, ¡estupendo!, porque es justo lo que hicimos, acertamos la predicción!. con lo cual no tenemos burbujas ni atascos, sigue la producción normal.
Pero si resulta que nos hemos equivocado con la prediccion y teníamos que seguir con monovolúmenes, ahora tenemos a los equipos de trabajo 1, 2 y 3 con deportivos que tenemos que tirar, o sea, vaciar la cadena de montaje entera y ponernos a fabricar monovolúmenes.
Esto es lo que se conoce como vaciar el pipeline, y en procesadores con un pipeline con muchas etapas supone un problema muy grande, porque el rendimiento cae en picado.
Si la cadena de montaje tiene 4 equipos (pipeline de 4 etapas) al ser ahora como si empezásemos a fabricar de nuevo (porque tenemos la fábrica vacía) estaremos cuatro turnos de trabajo sin sacar ningún coche de la cadena de montaje, pero si el pipeline es de 8 etapas, estaremos 8 turnos.
Los últimos Pentium 4 (los Prescott) tenían un pipeline de más de 30 etapas, ¿entendemos ahora el problema que suponía que pasase esto con uno de estos procesadores? Es por esto que los pentium 4 invertían muchos recursos en tener una prediccion de saltos lo mejor posible, porque no podían darse el lujo de vaciar el pipeline dado que el impacto en el rendimiento era muy negativo.2.7.2.-Riesgos estructurales
Ocurre cuando el hardware no puede manejar la combinación de instrucciones que tiene "entre manos" en este momento. O sea, que por ejemplo no puede estar procesando la fase de lectura de la instruccion que está en esa fase, y la fase de escritura que está en la fase de escritura. Por algún motivo digamos que la "fábrica" no puede hacer esas dos cosas a la vez, aunque cada tarea la haga un equipo diferente. En este ejemplo la fase de lectura y la de escritura han de acceder ambas a la memoria, y es posible que no puedan acceder al mismo tiempo.
Realmente esto es complicado de explicar, no olvidemos que por ejemplo un procesador actual puede funcionar a 3000 o incluso 4000 mhz, pero la actual memoria DDR3 suele funcionar a 1600. Es por esto que el procesador no puede acceder a la memoria en todos sus ciclos, con lo que si para realizar una tarea forzosamente se necesita un dato que no está en la caché del procesador, tendrá que leerlo de la memoria RAM, el procesador tendrá que esperar hasta que pueda leer la RAM, y esto puede suponer varios ciclos o "turnos de trabajo".
En el ejemplo anterior del equipo 1 que se "atascó" con el coche naranja puede ser que les faltase una pieza del chasis y tuviesen que esperar dos horas hasta que viniera en transportista con esa pieza.En definitiva, la realidad dista mucho de esa situación inicial que planteábamos donde al principio y hasta que el primer coche llegaba al último equipo de trabajo, la producción no estaba al 100%, pero una vez ocurría esto, ya producíamos sin problemas "a todo trapo" con todos los equipos siempre trabajando.2.7.3.-Riesgos de datos
Esto pasa cuando una instrucción depende del resultado de una instrucción anterior.
Por ejemplo, tenemos una instrucción que es:
"en una cajita llamada numero_total guarda el resultado de sumar 5+3"
Y la siguiente instruccion es:
"Dividir el número que está guardado en la cajita llamada numero_total por dos".
¿Como vamos a dividir el número si aún no sabemos cual es el número? hasta que la instrucción que suma 5+1 no salga de la fábrica no podemos empezar a "construir" la nueva instrucción.
Si bien con ese escenario ideal, dos procesadores, ambos a 1000 mhz rendirían casi lo mismo, independientemente de las etapas del pipeline, la realidad es que no es asi, y el procesador con el pipeline con más etapas tendría que ir a más frecuencia para así contrarrestar las caídas de rendimiento que hemos comentado en este punto.
Una cosa es la velocidad máxima de producción en intrucciones por ciclo, o "coches por hora", y otra diferente es la velocidad media procesando un programa.
3.-Conclusiones
Antes de nada agradecer a los que hayáis leído hasta aquí, y felicitaros, porque hemos visto juntos bastantes facetas del funcionamiento interno de un procesador, lo cual permite entenderlo un poco mejor.
Ya tenemos una idea clara de qué es el pipeline y cómo afecta al rendimiento y posibilidad de aumentar la frecuencia.
No hemos visto cómo funciona un procesador con Hyperthreading, ni siquiera un procesador multinúcleo, cuando a estas alturas casi cualquier procesador tiene un mínimo de dos núcleos, pero son cosas que iremos viendo juntos en futuros artículos.
¿Te ha gustado este artículo? Te recomendamos...
- Desmontando mitos informáticos: Las tarjetas gráficas con "muchos megas"
- REVIEW: Equipo servidor descargas/HTPC bajo consumo y ruido
- REVIEW: Comparativa de ruido de fuentes de alimentación
- ¿Cuánto consume un disco duro? - Comparativa
- ¿Son fiables los discos SSD?
El redactor de este artículo es colaborador de forodvd en los foros de Informática general y HTPC, y responsable de elhtpc.es


No tengo palabras Tassadar. Impresionante.
Mi más sincera enhorabuena por este articulazo (y por muchos otros con los que nos deleitas).
He aprendido cosas nuevas gracias a él, aunque creo que lo deberé leer de nuevo para sacarle más jugo.
Excelente Tassadar, enhorabuena.
Mi Blog.
JC
Enhorabuena Tassadar! pedazo de artículo.
Ya sabía lo que era el pipeline, pero estos artículos están guays sobre todo para coger ideas de como explicarlo si alguna vez surge la ocasión, en mi caso soy programador y son muchas las veces que me toca. Así que gracias!!
EQUIPO ACTUAL
OLED 55" SONY XR-55A90J Bravia Master Series 4K Ultra HD
EDGE-LED 49" Sony KD-49XF8096 UHD 4K HDR X-Reality PRO
LED 22" Samsung UE22C4000 blanco HD Ready
Bluray Samsung BD-F6500 3D
Yamaha YAS101 (Barra de sonido) + YAMAHA YST-SW030
PS5 Slim 1 TB // PS1 Original // Sega Master System 2 // SNES Mini
KODI MEDIA CENTER [J3455 4Gb RAM, SSD 120 Gb, 10 TB]
POST-PLEX-MEDIA-CENTER
Gracias a todos!!!
Yo también soy programador, y aunque para programar a estas alturas de procesadores multinúcleo y velocidades de varios ghz ya no se estila el optimizar código (cuando precisamente por el multinúcleo sería muy positivo), ni el tener en cuenta estas cosas para mejorar el rendimiento, son temas muy interesantes que creo que merece la pena conocer, al menos tener una idea de qué es y que implica.
Un saludo
Última edición por Tassadar; 17/01/2014 a las 12:49


Impresionante, mis felicitaciones Tassadar.
MEJORES PELICULAS FORODVD 2024: RESULTADOS
Cómo subir fotos a Forodvd --> click
Patrones: Blanco 100% Magenta 100% Gris 5%
LO MÍO (si tenéis curiosidad, pinchad en el enlace)
LG 65CX6LA
NAD T778 + MA Silver 100 6G + Silver C150 + Bronze 1 + SVS SB1000 Pro
Panasonic BDT110
Panasonic 42V20
Si se calienta la CPU el mejor refrigerante es ..... una Estrella Galicia
En dos palabras: ''Im-prezionante''. Me has dejado con la boca abierta macho. No tenía ni pajolera idea de lo que era el pipeline (me sonaba a una canción de Alan Parsons
PD: Para que escuches la canción:
Muchas gracias Navone y Supergontzo!!
PD: La canción mola, jeje, estaría genial para un video que explicase el pipeline xD
Última edición por Tassadar; 18/01/2014 a las 09:53
Menos mal que he dejado de leer cuando lo recomiendas...sino aún seguiría perdido en el limbo!!!
Enhorabuena, gracias a gente como tú, haces que este foro sea la rehostia.
Saludos
SONY 40"X4500 Está muerta, 2000 y pico a la basura al 4º año. Mucha gama alta pero...Basura. ahora tengo:
Samsung ES6800 Ofertón de Redcoon con la selección Española, 4 a los Italianos, y 40% de descuento pa mi.
SONY 32"V5500
PLAY3 FAT
Denon X2800H
QAcoustics 2x1050
QAcoustics 2x1030
SVS 1000
QAcoustics 1010c
Muchas gracias Tassadar, hoy me siento un poquito menos ignorante en temas de Hardware. Espero con ganas tu próximo articulo sobre el tema.
Impresionante!!
 Permisos de publicación
Permisos de publicación

